This feature is currently in Private Preview.
- Must be enabled by Tecton Support.
- Available for Spark-based Feature Views -- coming to Rift in a future release.
- See additional limitations & requirements below.
Data Compaction
In Performance and Costs of Aggregation Features we introduced the high-level architecture of Tecton's Aggregation Engine:
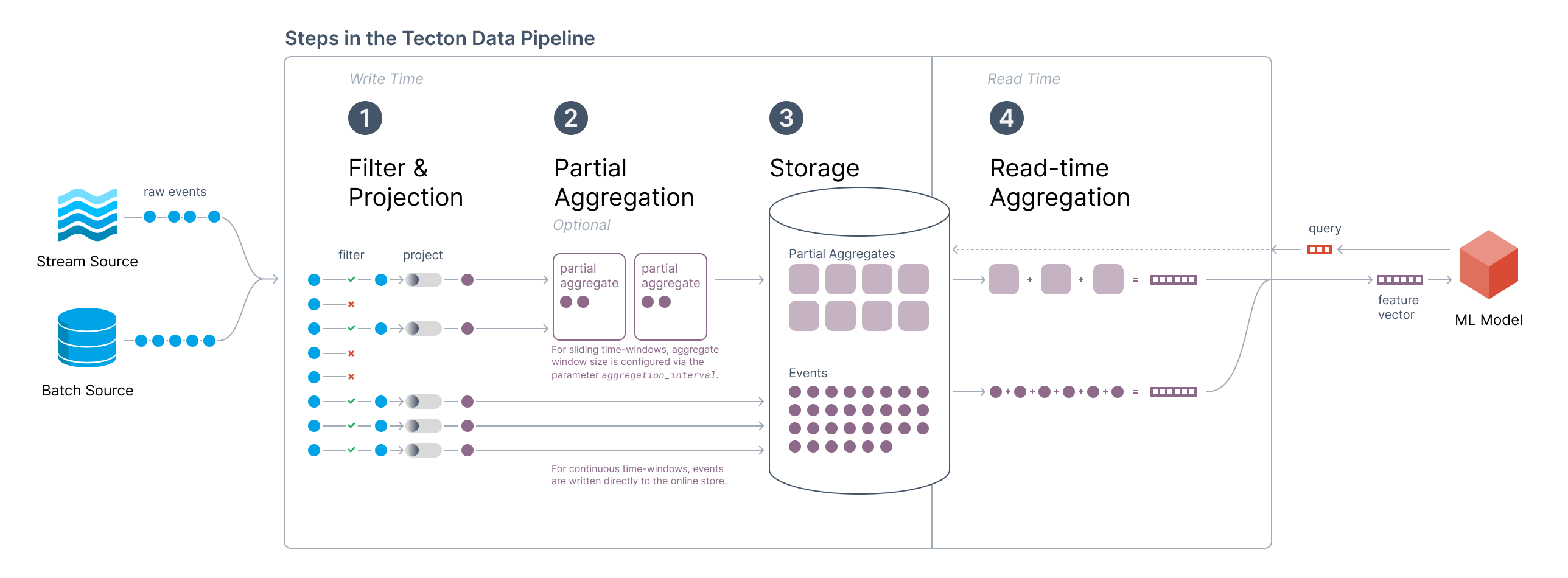
With Data Compaction, Tecton significantly optimizes the performance of aggregation features. Underlying this optimization are data compaction processes that Tecton automates and runs behind the scenes.
As a result, Tecton users will automatically see the following benefits:
- Low Latency Serving for large time windows: Users will observe extremely fast online retrieval times for aggregations - even in cases when aggregation time windows are very long, or the number of events in a fixed time window is very high (>> 100,000)
- Optimized Online Storage Efficiency: Users will see even fewer online store writes during backfills, reducing the maintenance burden and cost of the online store (see documentation)
- Batch Healing of Streaming Features: Streaming Features can automatically be corrected with batch data
Architecture Overview
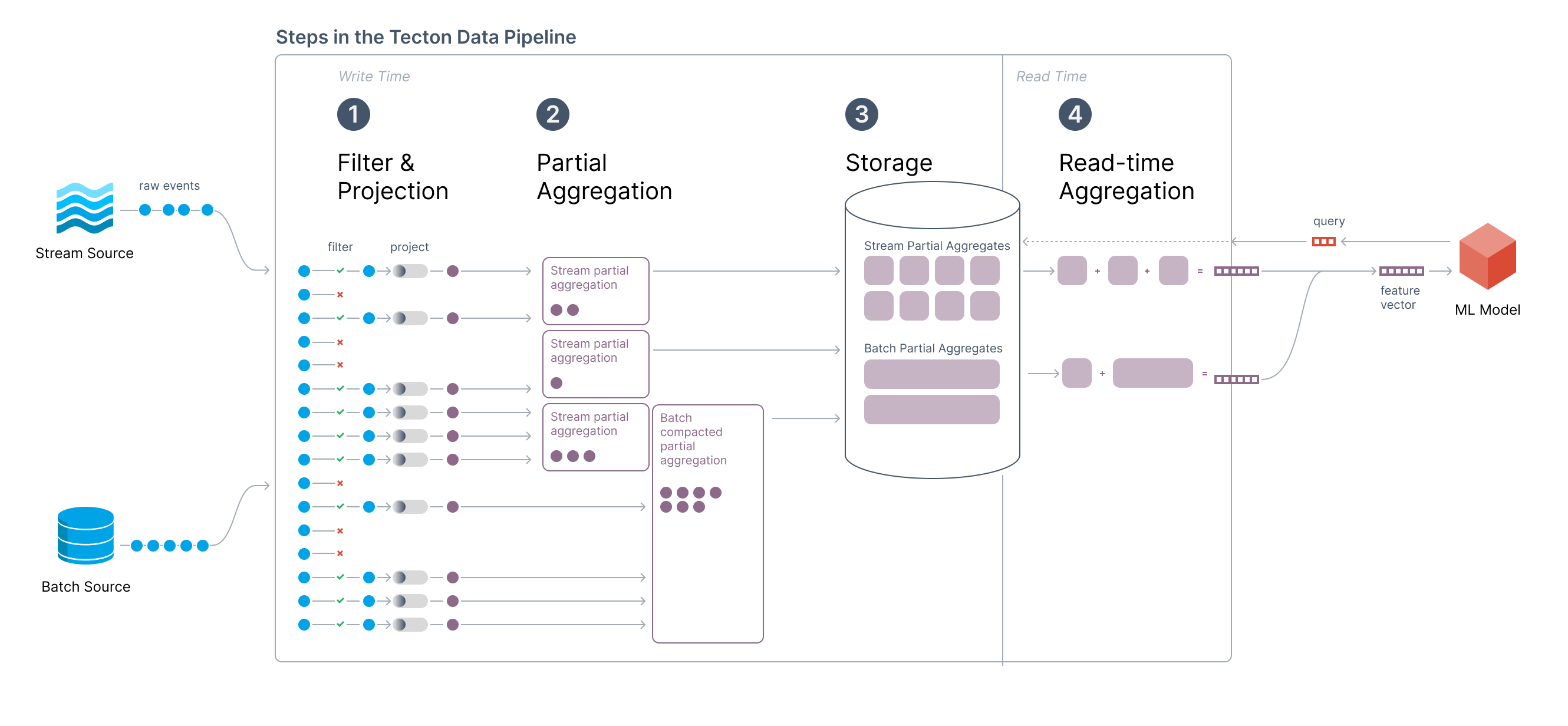
Conceptual Overview
The key innovation is to replace small, old tiles with fewer “compacted” tiles to reduce the amount of data processed at read time. The Tecton service takes care of piecing together the different data points while presenting a consistent and simple API to the consumer.
Compaction is performed by a periodic offline process that reads the event log, performs the partial aggregation, and updates the Online Store. At read-time, Tecton handles rolling up the final aggregation over varying partial aggregate “tile” sizes.
Batch Updates to the Online Store
On a pre-defined cadence – typically daily – Tecton will rebuild tiles in the Online Store based on data available in the Offline Store. A data processing job will read the offline data for the full aggregation window, perform partial aggregations at the optimal tile size, and update the Online Store for each key.
Combining Stream and Batch values
As new events arrive on the Stream, they continue to be written directly to the Online Store as well. When a query is sent to the Tecton Feature Server, Tecton reads both the ‘batch updated’ table and the ‘stream updated’ table and aggregates the final feature value. To avoid double counting, Tecton tracks the latest value written to the batch table and only reads stream events greater than that timestamp.
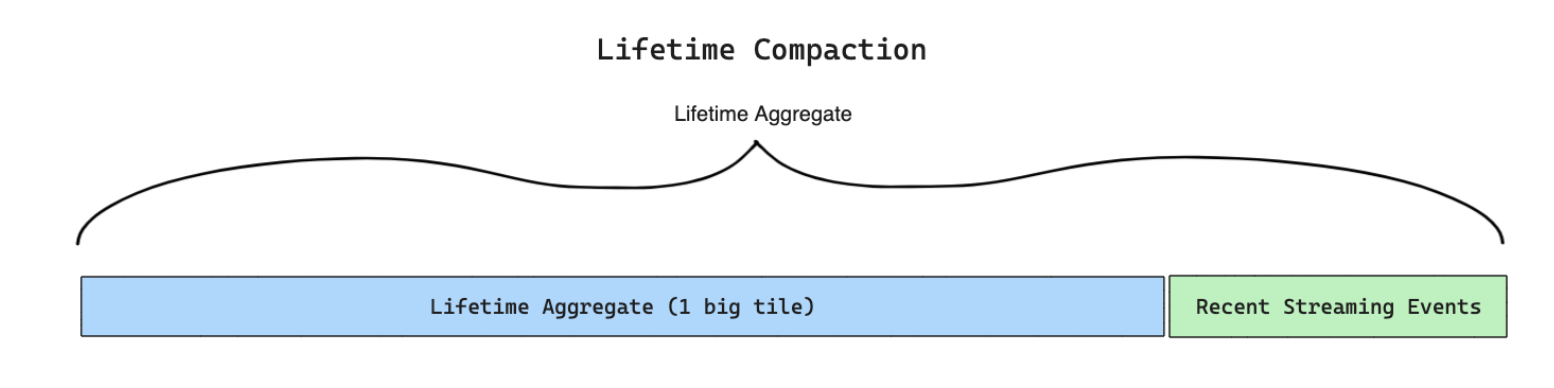
Lifetime Aggregates
The simplest scenario is a lifetime aggregation feature. In this case, the system never expires old events.
During the batch update process, Tecton will update a single tile per key that covers the full lifetime of the feature data. At read time, Tecton will combine the “big tile” with streaming events since the last batch update.
Enable Data Compaction for a Batch Feature View
To enable data compaction for Batch Feature View, you must set
compaction_enabled=True:
- Example (without Aggregations)
- Example (with Aggregations)
from tecton import batch_feature_view
from datetime import timedelta, datetime
@batch_feature_view(
sources=[transactions],
mode="spark_sql",
entities=[user],
feature_start_time=datetime(2022, 5, 1),
batch_schedule=timedelta(days=1),
online=True,
offline=True,
compaction_enabled=True,
tecton_materialization_runtime="0.8.2",
)
def user_average_transaction_amount(transactions):
return f"SELECT user_id, timestamp, amount FROM {transactions}"
from tecton import batch_feature_view, Aggregation, LifetimeWindow, TimeWindow
from datetime import timedelta, datetime
@batch_feature_view(
sources=[transactions],
mode="spark_sql",
entities=[user],
aggregations=[
Aggregation(column="amount", function="sum", time_window=LifetimeWindow()),
Aggregation(column="amount", function="sum", time_window=TimeWindow(window_size=timedelta(days=7))),
],
feature_start_time=datetime(2022, 5, 1),
lifetime_start_time=datetime(2022, 5, 1),
batch_schedule=timedelta(days=1),
online=True,
offline=True,
compaction_enabled=True,
tecton_materialization_runtime="0.8.2",
)
def user_average_transaction_amount(transactions):
return f"SELECT user_id, timestamp, amount FROM {transactions}"
Enable Data Compaction for a Stream Feature View
- Set
compaction_enabled=Trueon your Stream Feature View. - Optionally set
stream_tiling_enabled(defaults toFalse)- If
stream_tiling_enabled=False, stream data will not be tiled and the Feature View will be in Continuous Mode. - If
stream_tiling_enabled=True, Tecton will determine the appropriate tiling size for the online store and tile the stream data accordingly.
- If
from tecton import stream_feature_view, FilteredSource, Aggregation, LifetimeWindow
from datetime import timedelta, datetime
@stream_feature_view(
source=FilteredSource(stream),
entities=[user],
mode="pyspark",
online=True,
offline=True,
aggregations=[
Aggregation(column="clicked", function="count", time_window=LifetimeWindow()),
],
feature_start_time=datetime(2024, 3, 1),
lifetime_start_time=datetime(2024, 3, 1),
batch_schedule=timedelta(days=1),
compaction_enabled=True,
stream_tiling_enabled=False, # Determines whether the stream data is tiled in the online store.
tecton_materialization_runtime="0.9.0",
)
def user_click_counts_compacted(ad_impressions):
return ad_impressions.select(ad_impressions["user_uuid"].alias("user_id"), "clicked", "timestamp")
Limitations & Requirements
Compaction is available for Spark-based Feature Views -- support for the Rift compute engine is coming soon.
Compaction currently supports Feature Views that use DynamoDB for the Online Store.
Batch Feature Views
To use compaction_enabled=True for a Batch Feature View, the Feature View
must:
- Have
online=Trueandoffline=True. - Have
batch_schedule=timedelta(days=1). - Use Delta for the offline store, either with
OfflineStoreConfig(staging_table_format=DeltaConfig())or in the repo configuration file. Note that Delta is the default offline store format in Tecton 0.8+. - Have a
tecton_materialization_runtimeof'0.8.2'or greater.
Note that during the Private Preview, Batch Feature Views using Compaction with
a Tecton Aggregation must use a
TimeWindow or
LifetimeWindow. Support for
TimeWindowSeries is coming soon.
Stream Feature Views
To use compaction_enabled=True or stream_tiling_enabled=True for a Stream
Feature View, the Feature View must:
- Meet the same requirements as above (i.e. to use Compaction for a Batch Feature View).
- Not use the
aggregation_intervalparameter. - Have a
tecton_materialization_runtimeof'0.9.0'or greater.
Note that during the Private Preview, Compaction is supported for Stream Feature Views that:
- Use Tecton Aggregations
- Use a
LifetimeWindow - Do not use the Ingest API
Support for these capabilities (Stream Feature Views that use TimeWindow or
TimeWindowSeries, that don't use Aggregations, or that use the
Ingest API)
is coming soon.
Enabling Data Compaction for Existing Feature Views
Tecton recommends that customers first test this capability on Feature Views in a staging environment before enabling it for existing production Feature Views. Note that enabling Data Compaction on an existing Feature View will require rematerialization of feature data — however, Tecton’s optimizations make backfills cost efficient in most scenarios.